Thoughts about stackdb
I was originally planning to build a fully distributed double-entry bookkeeping program, that doesn't depend on a server at all. But how do I build that stuff?
I've drawn some sketches about the structure then they gave me a conclusion: I must build purely client-side distributed database in JavaScript. That's the stackdb.
In this article, I'll share about my thoughts about how I came up with this idea, how it'll be structured, and how it'll work.
How I came up with this idea
I was thinking of fully distributed system, that can sync each other without a server. But it's good to back-up the database on the server - we can always pull them out if we lost the device. Still, it feels creepy to store my accounting ledgers in someone else's computer. Of course it'd be my server - so I'm fine - but what about someone else?
So I thought about encrypting then saving the data to server, storing the key on the client. It's good, but, who manages the data? Who'll resolve the confliction between two devices? Distributed database with master-master replication to the rescue.
CouchDB (or PouchDB in this case) looked pretty promising, but it's really complicated to show modification history - not important for personal use - but it's really important for corporate use, since it can be used for audit or something. (Not saying that it'll be used in corporates, that's crazy)
That being said, the structure became something similiar to git. I need version history, merging, distribution. So I looked for it and found Noms. It looks good, but it looks so complicated and it hasn't matured yet - so I decided to build a simple distributed and versioned database system.
After designing few concepts about the database, it became Redux with a replay feature. Maybe I could use Redux to build the database! ...Maybe.
Concept
stackdb would be a simple database - it'll be separated to 3 parts.
I'm not sure if stackdb is even a database - it stores a list of transactions, then current state gets built by the view schema.
Current state
Current state stores the current state of the database, usable by the program. It'll be stored in each client's database. It doesn't get transfered to other clients though, since it can be easily built using transactions data.
To edit the current state, the client must issue new transaction. The transaction data varies app to app.
Transactions
The transaction data. It stores how the data should be modified to process the request, like a diff file. It'll be shared between each client, and it'll be merged every time sync occurs. Basically, it's a complete history how the database was built.
View schema
View schema describes how the 'current state' should be built. It'll read every transaction on the database then return the current state. Some view schema can depend on other view schema to save time, thus working as indexes.
Some view schema can be generated temporarily, and they won't get stored in the database. They'll be 'queries', useful for searching stuff, sorting, etc.
Syncing
stackdb is fully distributed database, that devices are disconnected from each other almost every time. Thus it needs to provide reliable syncing mechanism.
Unless each transaction overwrites same field, it can just merge them in any order. But if not, that's a conflict, and it must be resolved before doing anything else.
Transaction list data type
To store transaction list with multiple parents support, we could use linked list, but that'd be really complicated and slow - furthermore, we should be able to store them in JSON file. Perhaps it could 'rebase' every conflict, making only one parent can exist. That way, it can scan the transaction list much much faster. It'll tamper with the history, though.
Merging algorithm
Merging algorithm would be pretty complicated, because transactions are placed in a single list. To store parent information, it'd use relative offsets to link the parents.
This is old version of the algorithm:
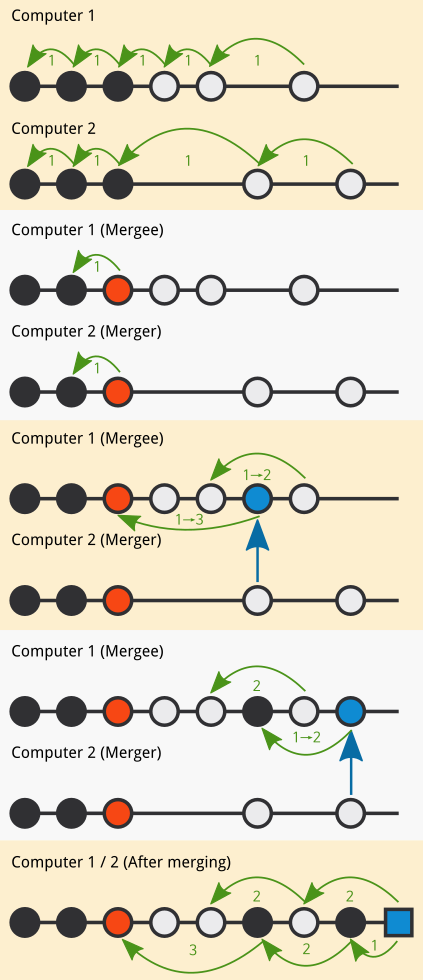
Finding mutual parent
Finding mutual parent can be done by reversing transactions by following parents, then checking each node if they are same node with same parent distance(s). If 'merging' node appears, simply following any parent will work (But it should be same between two computers).
If one side hasn't made any transaction yet, we can skip rest of merging algorithm - it can be 'fast forwarded'.
I'm not sure if there are any failing cases about this, though.
Conflict detection
Before merging the transactions, the conflict detector should detect if both branches conflict. The conflict detector would be feeded by each transaction on branch, and it would output conflicting transactions.
If there are any conflicting transactions, it should be handled. The conflict handler would process the transactions and convert them into 'fixed' transactions, while keeping the original version in the data.
Ordering transactions
Since the transactions are stored in linear array, the algorithm must order the transactions.
This is old version of the algorithm:
This is done by choosing 'merger' and 'mergee'. Usually branch with lower transactions count will be chosen as 'merger'.
Merger's transactions are 'spliced' into the mergee's transaction list. While doing this, parent indexes must be updated. While updating this, the algorithm would construct internal linked list and reverse children lookup indexes to make the operation much faster (splicing an array takes O(n^2) time, while linked list takes O(1) time, if it already has the node as variable.)
Or, it could build new output array. I'm thinking about what'd be efficient.
Transaction order can be anything; But it should be deterministic to prevent weird stuff from happening. Usually the commit date would be used to order them, though.
I've found a better way to order the transactions. Just like doing merge sort, it could look first transactions of each list and put them into the new array. This is actually much much cheaper than old algorithm.
But it needs to reset the parent indexes too. This can be really simplified, it could just store parent indexes array, which its size never changes. When adding new transaction, it can just get current index and parent index in indexes array and set the parent as the difference between two indexes.
This algorithm will be performed in O(n) time, since everything is already sorted and we just have to recalculate the parent indexes. That's it!
Additionally, the algorithm would be purely functional, which means that it doesn't do any mutation to the input. I can't believe I couldn't think of this really simple solution.
Creating 'merge' transaction
After ordering the transactions, it needs to finalize it by creating 'merge' transaction, which has two parents. After that, the merging finalizes and the current state updates to reflect merged state.
Database locking
The database must be locked while syncing; because the transaction list changes often. Since it doesn't need to respond immediately, it can wait until the syncing completes.
Conflict resolution
Conflict can be resolved by dropping a transaction with lower priority - but that's bad. Maybe we could the transaction to 'graveyard', and let the user solve the conflict, since consistency is so important for the bookkeeping program. But if the user is building fast-paced program like games and stuff - that's almost impossible.
Conflict resolution part would be separated to these parts, but the program must specify them to database since the database doesn't know how the transaction would affect the state.
- Conflict detector
- Transaction score determiner
- Conflict handler
- It could mark dropped transaction as 'failed', and view schema could detect that.
- It could just remove them from transaction list.
- It could remove both from transaction list, then mark it as failed.
- Or it could merge them into one.
Conflict detector
Conflict detector accepts two branches with common ancestor, and merges them into linear array, a.k.a. rebasing. It would work in O(n^2) time, or it might be cheaper. Anyway, It should return merged array and 'rejected' transactions. Rejected transactions would be passed to conflict handler.
Conflict handler
Conflict handler receives merged array and rejected transactions. It should resolve the rejected transactions by its own mechanism, and return the final merged array. The merged array gets processed by view schema and the syncing completes.
Storing current state
We need to reverse the current state in order to perform merging. Since we can't reverse the state, we must build the state from the beginning if we weren't storing previous results. Obviously, we can't store every current state for every transaction, but we can store 'sync point' for each remote devices, using that for restoring current state.
Accessor
Obviously, we can directly access the database if each database runs in the client, but what if it doesn't?
It needs some kind of protocol for accessing the database. Something like GraphQL? Maybe? But that's not required for now, since the program I'm trying to build assumes that every device has its own database.
But if that can't happen, it'll need access protocol. Since it doesn't need that now, I'm not gonna think about it.
Signing
Each transaction can be signed in order to verify who has written the transaction (Thus extermely useful for audit, etc). Since each transaction is schemaless, this can be easily implemented on the client side.
Encryption
I said about encryption earlier this article. It needs to support encryption, and/or 'blind' management of the database.
So I thought about encrypting then saving the data to server, storing the key on the client.
Well, encryption is trivial since it can encrypt the whole database file, but it needs one feature: blind management of the database. I made up that word, though.
Well, the concept is this: The server should blindly manage the transaction logs, without knowing what's inside that. Clients would share the key each other, but server'll never know the key.
Basic metadata should be known to the server, like the list of registered clients, Each client's sync position, etc. Other than that, server don't know everything.
But since it needs to read the transaction logs to merge branches, the client handles the merging. Thus this'll happen:
- Lock the database. (Not sure if this is necessary)
- Download new transactions.
- Merge the transactions.
- Upload the merged transactions.
- Unlock the database.
It's inefficient, but it'll be good for encryption. One catch is that while merging, merging client can 'hide' a commit from the database. Other than that, it's fine.
It could prevent hiding by using a signature - thus preventing modification. Or, it could only change indices then append 'fix transaction' that fixes error of the database.
Conclusion
This article is still work in progress. I'll update the article soon.